Overview of UAD
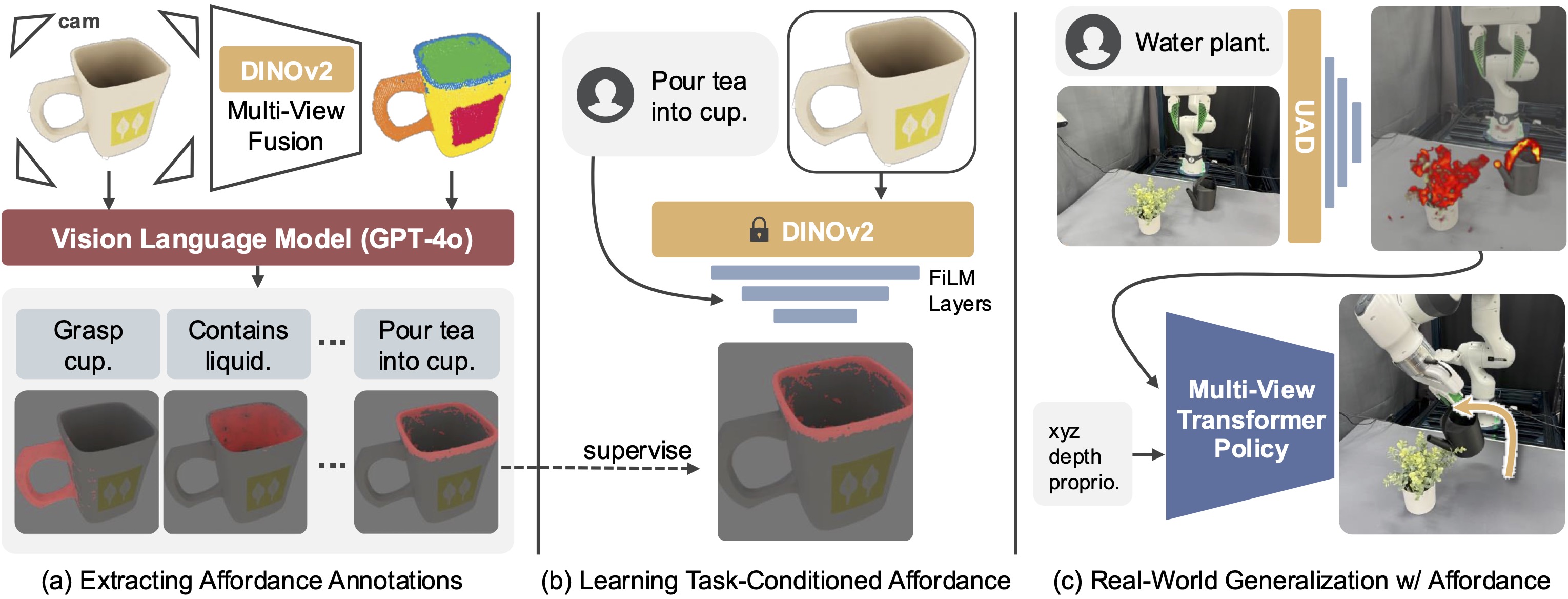
Using renderings of 3D objects, we first perform multi-view fusion of DINOv2 features and clustering to obtain fine-grained semantic regions of objects, which are then fed to VLM for proposing relevant tasks and corresponding regions (a). The extracted affordance is then distilled by training a language-conditioning FiLM atop frozen DINOv2 features (b). The learned task-conditioned affordance model provides in-the-wild prediction for diverse fine-grained regions, which are used as observation space for manipulation policies (c).
Task-Conditioned Affordance Prediction


Leveraging pre-trained features, UAD can seamlessly generalize to real-world robotic scenes, and even to human activities.
Interactive Affordance Demo
Waking the model…
Generalization Properties for Policy Learning
Using affordance as a task-conditioned visual representation, policies learned from as few as 10 demonstrations generalize to novel poses, instances, categories, and even to novel instructions, all in a zero-shot manner. Here we show examples of the generalization settings for three tasks in simulation: pour, open, and insertion.
Pouring: hold liquid container and pour into bowl
Training Scenario
Unseen Pose
Unseen Instance
(beer bottle & bowl)
Unseen Category
(beer bottle → coke can)
Unseen Instruction
(pour beer → water plant)
Opening: grasp and pull open revolute cabinet door
Training Scenario
Unseen Pose
Unseen Instance
Unseen Category
(cabinet → fridge)
Insertion: pick pen and insert into pen holder
Training Scenario
Unseen Pose
Unseen Instance (marker)
Unseen Category
(pen holder → cup)
Unseen Instruction
(insert pen → insert carrot)
Real-World Robot Execution
We further show that UAD-based policies can solve real-world tasks. Each policy is trained on 10 demonstrations.